La clasificación de datos es el proceso de identificar y catalogar los datos que tiene una organización, en base a una taxonomía definida.
En el contexto de la privacidad, la clasificación de datos es uno de los problemas más complejos. Tal como mencionamos en el post anterior de esta serie, aunque no es el problema más visible (como los avisos de privacidad y los checkboxes de consentimiento) sí es el más importante.
Lo anterior es fácilmente explicable para cualquier organización interesada en cumplir seriamente con la legislación de protección de datos personales.
La ley exige, entre otras cosas, documentación sobre los procesos de tratamiento, el cumplimiento efectivo de los derechos ARSOP de los titulares y una adecuada gestión de los consentimientos.
Pero, ¿cómo respondes cuando no conoces la realidad operativa de tu negocio?
El propósito de un sistema es lo que hace.
— Stafford Beer
La necesidad actual
Entre las soluciones más buscadas hoy por las empresas está, casi sin excepción, la generación rápida y sencilla de RATs (Registro de Actividades de Tratamiento). Tiene todo el sentido del mundo, ya que aunque la ley no detalla exhaustivamente su forma ni nivel de granularidad (eso quedó para la Agencia) en la práctica el RAT se transforma en la pieza central para demostrar cumplimiento.
El problema aparece al momento de completarlos de forma adecuada y fiel a la realidad. Estos documentos suelen ser elaborados por equipos legales o DPDs (Delegados de Protección de Datos). Pero en la práctica, buena parte de los flujos de tratamiento reales se definen tras bambalinas, en el software.
En organizaciones medianas o grandes, intervienen muchas personas; distintos equipos modifican partes del sistema, el código es extenso, vive en múltiples stacks tecnológicos, coexiste con software adquirido (CRMs, ERPs, entre otros) y evoluciona constantemente.
En ese contexto, resulta muy difícil que una sola persona o incluso un área completa tenga una visión real de qué datos se utilizan, para qué fines y por qué.
Es así como los RATs terminan construyéndose, muchas veces, sobre declaraciones de intención: lo que creemos que hace el sistema, o lo que pensamos que debería hacer. En el mejor de los casos, se realizan entrevistas a distintos equipos para levantar procesos y documentarlos. Pero ese esfuerzo se vuelve obsoleto rápidamente porque las organizaciones son organismos vivos, con procesos, software, equipos y cultura que muta constantemente.
Con el tiempo, la documentación se va alejando de lo que realmente sucede en el sistema. La manera más fiable de conocer la realidad operativa es estudiando el código como fuente de verdad.
Parafraseando a Stafford Beer: los sistemas son lo que son, no lo que creemos que deberían ser . Y ese entendimiento no se logra sin partir por un inventario de los sistemas y la clasificación de los datos que existen.
Una declaración de intenciones no resiste a una auditoría de la agencia fiscalizadora ni al ejercicio de derechos por parte de los titulares.
Distintos abordajes del problema
Para resolver el problema de la clasificación de datos, se pueden considerar dos tipos de soluciones: manuales y automáticas. Dentro de las soluciones automatizadas, existen aquellas basadas en reglas estáticas — principalmente expresiones regulares (regex) — y aquellas basadas en modelos de inteligencia artificial, como Large Language Models (LLMs).
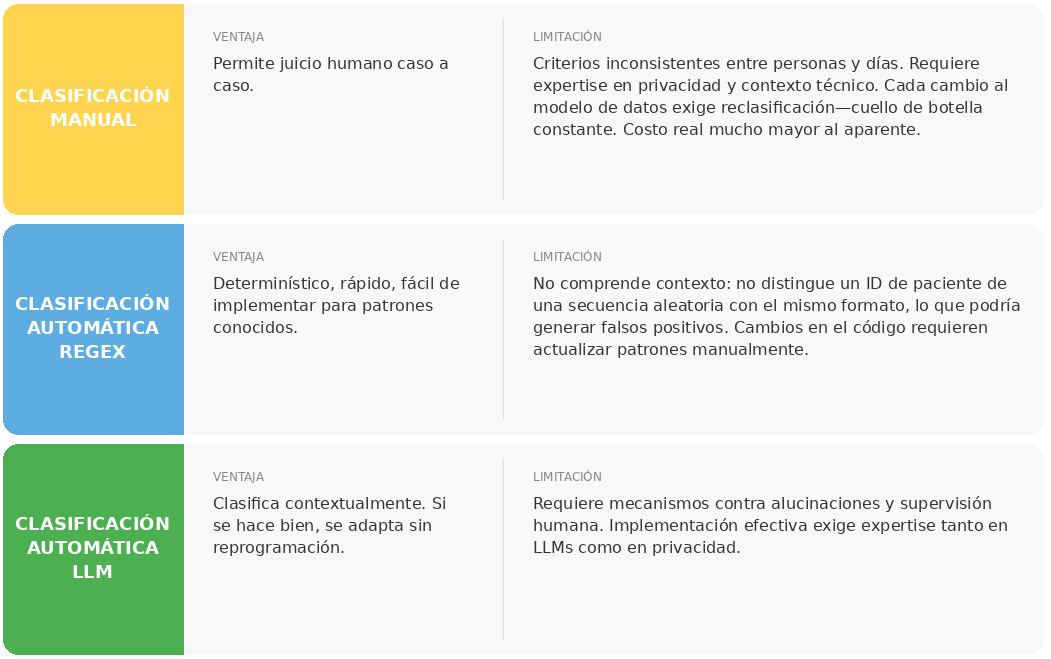
El abordaje manual
Suele ser el primero que se considera. Sin embargo, presenta múltiples limitaciones. Es intensivo en trabajo, depende fuertemente de criterios que varían de una persona a otra (e incluso de un día a otro) y requiere un nivel de conocimiento especializado en privacidad que, en general, no está disponible.
Además, la clasificación de datos es inherentemente contextual. Clasificar correctamente ciertos campos implica revisar no solo el nombre de una columna, sino su uso y su relación con otros datos. Esto termina trasladando una carga adicional al equipo de desarrollo, que debe invertir tiempo en una tarea que no es su foco principal.
Por estas razones, este enfoque resulta mucho más costoso de lo que parece. Y peor aún, no escala: cada cambio en el código requiere volver a clasificar, transformándose en un cuello de botella permanente para la evolución del sistema y el desarrollo de nuevas funcionalidades.
El uso de reglas estáticas (regex)
Surge como una primera alternativa frente a los problemas de la clasificación manual.
Este enfoque puede ser efectivo para identificar patrones bien definidos (por ejemplo, direcciones de correo electrónico, números de tarjetas) pero tiene límites claros. Como las reglas son rígidas, se necesita definir una por cada tipo de dato y cualquier variación en la forma de almacenar la información introduce errores. Si aparecen nuevos tipos de datos, o si estos se representan de manera distinta, el sistema deja de funcionar correctamente. Además, las regex carecen de contexto , por lo que detectan patrones pero no examinan el significado del dato ni su rol dentro del sistema.
Las soluciones automáticas con LLM
Ofrecen una alternativa más flexible. Permiten clasificar datos de manera contextual, adaptarse y evolucionar junto con el sistema. Así, se alinean mucho mejor con la realidad dinámica de las organizaciones.
Sin embargo, una buena implementación dista de ser trivial. Es necesario tomar medidas explícitas para reducir alucinaciones , incorporar supervisión humana y definir criterios claros. También hay otros riesgos: pasar datos personales a un agente puede exponer información sensible.
Entonces, ¿qué datos o documentos se estudiarán? ¿Cómo? Usar LLMs o agentes de forma efectiva requiere experiencia técnica , conocimiento profundo del dominio de privacidad y una sensibilidad desarrollada a partir del trabajo práctico con estos sistemas. En otras palabras, no basta con llegar y usar un modelo. Hay que saber guiarlo.
Nuestro enfoque
A partir de nuestra experiencia, optamos por un enfoque distinto a los habituales. Así, concebimos una estrategia híbrida capaz de clasificar revisando únicamente código, sin la necesidad de revisar los datos en las bases de datos en ningún momento.
Nuestro método se basa en un análisis sintáctico y semántico del código fuente , combinando modelos de lenguaje (LLMs), supervisión humana estratégica y procesos iterativos de refinamiento. De esta forma, entregamos al agente el contexto necesario para comprender qué hace el sistema y cómo se utilizan los datos, incluso cuando los campos o estructuras tienen nombres poco descriptivos.
Este diseño tiene una consecuencia clave y es que al poder trabajar únicamente sobre código, el enfoque resulta más seguro y más viable en la práctica. Los modelos nunca procesan datos personales reales y el código no se usa para entrenamiento.
Las organizaciones suelen ser reacias (con razón) a compartir datos, pero con las garantías de seguridad adecuadas, sí están dispuestas a dar acceso al código fuente. Así, combinamos automatización, contexto y control humano sin introducir riesgos innecesarios asociados a la exposición de información sensible.
Nuestra solución no se limita a la clasificación de datos personales, sino que incorpora también la clasificación de datos empresariales , un aspecto fundamental en organizaciones B2B.
Clasificar datos empresariales no es un ejercicio académico. Aunque la legislación de protección de datos personales se centra en personas naturales, esta práctica resulta clave para una organización B2B. Por ejemplo, para revisar contratos con terceros, restringir de forma más precisa el acceso interno a la información y sentar las bases para modelos de control de acceso como ABAC o RBAC, con impacto directo en ciberseguridad.
Criterio experto incorporado
Usar inteligencia artificial para realizar una clasificación no es tan simple como parece.
Toda clasificación automática enfrenta decisiones difíciles.
¿Dónde se coloca el trade off? ¿Qué errores son aceptables y cuáles no lo son?
Taxonomía y niveles de riesgo
Uno de los primeros desafíos es definir taxonomías que realmente tengan sentido. Clasificar no es solo asignar etiquetas, sino también definir categorías lo suficientemente atómicas para ser descriptivas, pero lo bastante operativas como para permitir el cumplimiento de exigencias legales y regulatorias.
A esto se suma la necesidad de asignar niveles de riesgo a cada dato, considerando tanto la sensibilidad del mismo como su uso efectivo.
Este es uno de los criterios que guía nuestro quehacer y que se resume en el principio positive-sum del marco de Privacy By Design (Ann Cavoukian): proteger adecuadamente la privacidad de las entidades que interactúan con la plataforma, sin sacrificar la operación del negocio. La privacidad no debe matar al sistema, ni quedar subordinada a la conveniencia técnica. Ambos deben coexistir e incluso, potenciarse.
Ambigüedad: un dilema ineludible
Uno de los problemas más complejos de la clasificación no es la falta de información, sino la ambigüedad inherente de ciertos campos. Esta ambigüedad suele manifestarse, al menos, en dos escenarios frecuentes.
En el primer caso, un mismo dato puede razonablemente atribuirse a distintos titulares según cómo se interprete.
Por ejemplo, en un negocio B2B donde una empresa emite boletas por servicios prestados a personas naturales, los datos de esa boleta son genuinamente ambiguos: el RUT y dirección del cliente son datos personales del receptor, pero también son registros tributarios que la empresa está legalmente obligada a conservar. Y si el servicio prestado revela información sensible (como una consulta médica, una asesoría legal) el contenido de la boleta adquiere otra dimensión. La pregunta no es si se puede eliminar el dato (no se puede), sino cómo se clasifica, quién puede acceder a él, y bajo qué condiciones. Frente a esta ambigüedad, nuestro criterio es claro: cuando el dato puede revelar información sensible sobre una persona natural, la clasificación debe reflejar ese nivel de protección , independientemente de su origen operacional o tributario.
En el segundo caso, el titular del dato puede variar según la situación. Un ejemplo típico es un sistema de mensajería o chat donde interactúan trabajadores de una empresa con usuarios (personas naturales). Dependiendo de quién envíe el mensaje, el contenido pertenece a uno u otro titular. Dado que estos campos abiertos pueden contener, en la práctica, cualquier tipo de información — incluida información sensible —, nuestro criterio técnico es tratarlos de forma conservadora como datos del usuario. Este enfoque reduce el riesgo de sobreexposición y errores de clasificación en escenarios donde la ambigüedad es estructural.
El arte de la clasificación
Todos estos ejemplos evidencian algo que hemos repetido con insistencia: clasificar bien requiere entender el dominio del negocio. La ambigüedad no se resuelve solo con patrones o nombres de campos, sino con una comprensión profunda de cómo se usa el sistema.
El desafío, entonces, es cómo lograr una clasificación automática que funcione en diferentes dominios sin perder criterio. Ahí es donde está el verdadero arte: abstraer reglas generales, codificarlas en prompts y procesos robustos y lograr que el sistema aplique estos principios de forma consistente, respetando tanto la diversidad de contextos como los límites de riesgo aceptables.
Ese nivel de criterio no se improvisa. Es el resultado de experiencia acumulada en el uso de agentes y en el campo de la privacidad y se refleja en decisiones concretas: reglas explícitas, justificaciones por campo y trazabilidad del porqué de cada etiqueta.
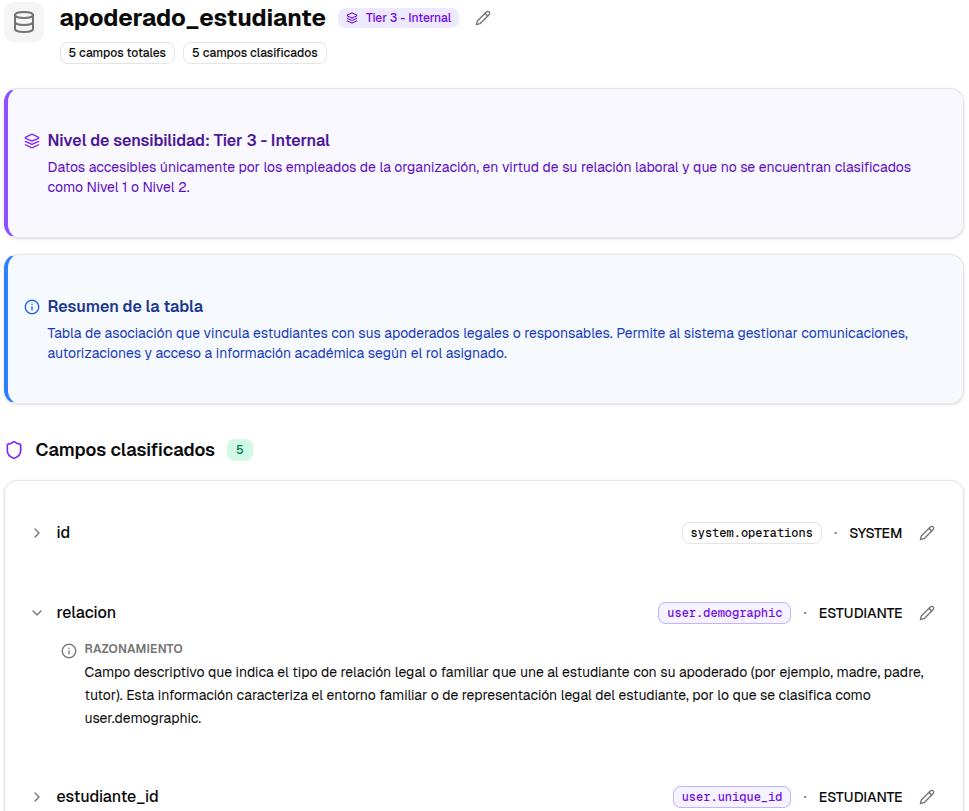
Validación
Para validar la efectividad del clasificador, lo evaluamos sobre un caso real: una empresa B2B con presencia en múltiples países de Latinoamérica.
Se trata de una plataforma con miles de campos que contienen información personal — incluyendo una gran cantidad de datos sensibles — y datos empresariales, tanto propios como de empresas clientes.
Por eso resulta un caso tan interesante y exigente para validar la herramienta. Aquí los errores tienen un costo real, existen flujos de alto riesgo y obligaciones de cumplimiento.
Diseñamos la validación como un proceso controlado. A partir del sistema completo, seleccionamos un conjunto de 2.173 campos distribuidos en 200 tablas, asegurando diversidad en tipos de tablas y cobertura de distintos procesos de negocio.
Sobre este muestreo se realizó una revisión manual experta , construyendo así un golden dataset. Posteriormente, se evaluaron campo a campo los resultados del clasificador automático sobre esta misma muestra, comparándolos con la revisión manual.
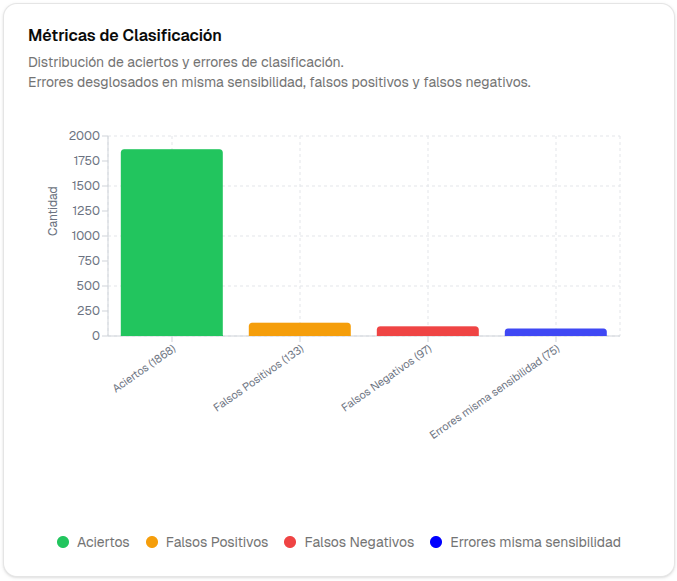
Sobre el muestreo completo, se obtuvo un 85.96% de precisión de la herramienta.
En el gráfico siguiente se desglosa la clasificación obtenida en cantidad de aciertos, falsos positivos, falsos negativos y errores de clasificación entre categorías de igual sensibilidad.
Para interpretar estos resultados, es necesario explicar el modelo de sensibilidad utilizado en el gráfico.
Cabe aclarar que esta es una simplificación con fines ilustrativos. Cuando trabajamos con una organización, los niveles de sensibilidad se definen con mucha mayor granularidad, considerando el contexto específico del negocio, sus obligaciones regulatorias y el uso efectivo de cada dato.
Dicho esto, para efectos de este análisis el modelo está orientado a reflejar cómo la ley define la sensibilidad:
-
Nivel 0 (menor sensibilidad): Datos empresariales.
-
Nivel 1: Datos personales no contemplados como sensibles por la ley.
-
Nivel 2 (mayor sensibilidad): Datos personales sensibles según la Ley 21.719.
De esta forma, decimos que un falso positivo ocurre cuando la herramienta asigna un nivel de sensibilidad mayor al que correspondía según la clasificación manual. Un falso negativo es cuando asigna un nivel menor al esperado. Finalmente, los errores de misma sensibilidad son aquellos donde la herramienta asigna una categoría taxonómica equivocada, pero dentro del mismo nivel de sensibilidad (por ejemplo, confundir un nombre completo con un email, ambos en nivel 1).
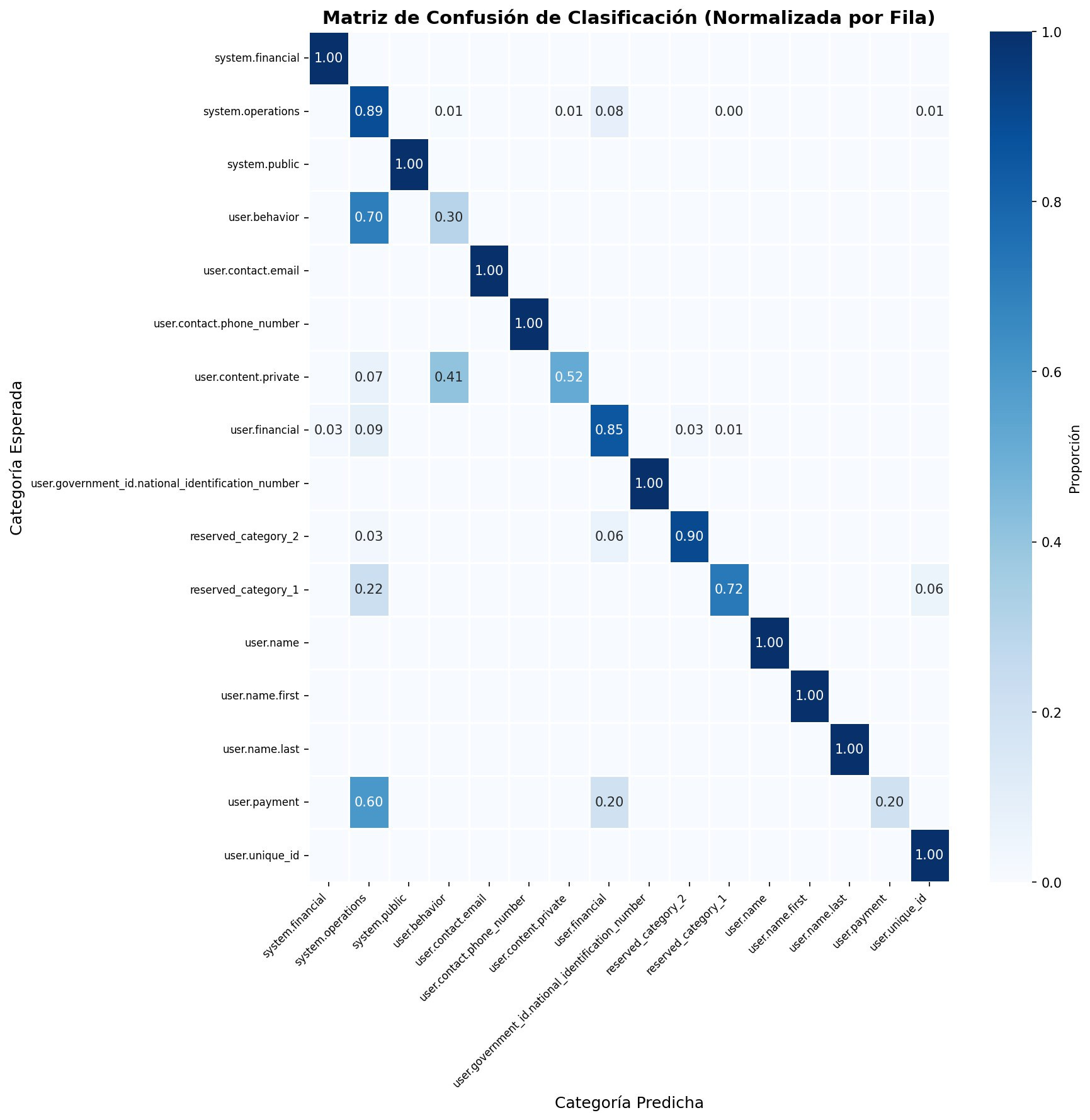
La matriz de confusión muestra en mayor detalle los resultados obtenidos. Cada fila representa la categoría esperada (clasificación manual) y cada columna la categoría predicha por la herramienta. Los valores en la diagonal indican los aciertos, mientras que los valores fuera de ella, los errores. Esta matriz se encuentra normalizada por fila, de modo que cada celda representa la proporción de datos de esa categoría que fueron clasificados de una u otra forma.
Por claridad, se muestran solo las 16 categorías con mayor cantidad de ocurrencias en el muestreo.
Discusión
Por medio de la validación realizada, nuestra herramienta de clasificación automática obtuvo una precisión del 85.96% sobre la muestra , consolidándose como un excelente resultado inicial.
Es importante recordar que este valor debe interpretarse a la luz de la complejidad del dominio. No se trata de datos homogéneos ni de esquemas simples, sino de sistemas reales, con campos ambiguos, usos múltiples y fronteras difusas entre datos personales y empresariales. Existen situaciones donde incluso dos expertos en el área podrían discrepar.
Así, lo relevante no es eliminar el error, sino entender su costo y minimizar los que realmente importan.
En clasificación de datos personales, los falsos negativos son más graves que los falsos positivos. Un dato sensible clasificado como no sensible queda expuesto a tratamientos inadecuados, pero un dato no sensible clasificado como sensible simplemente recibe protección adicional. El costo asimétrico de estos errores guía nuestras decisiones de diseño y preferimos ser conservadores cuando hay duda.
En la matriz de confusión hay unos casos que vale la pena analizar con más cuidado. Categorías como user.behavior y user.payment fueron frecuentemente clasificadas como system.operations. Esto ocurre en zonas donde existe solapamiento legítimo: un registro de uso de funcionalidades es, simultáneamente, comportamiento del usuario y telemetría operacional. El método de pago de una transacción es tanto un dato financiero del titular como un registro contable del negocio.
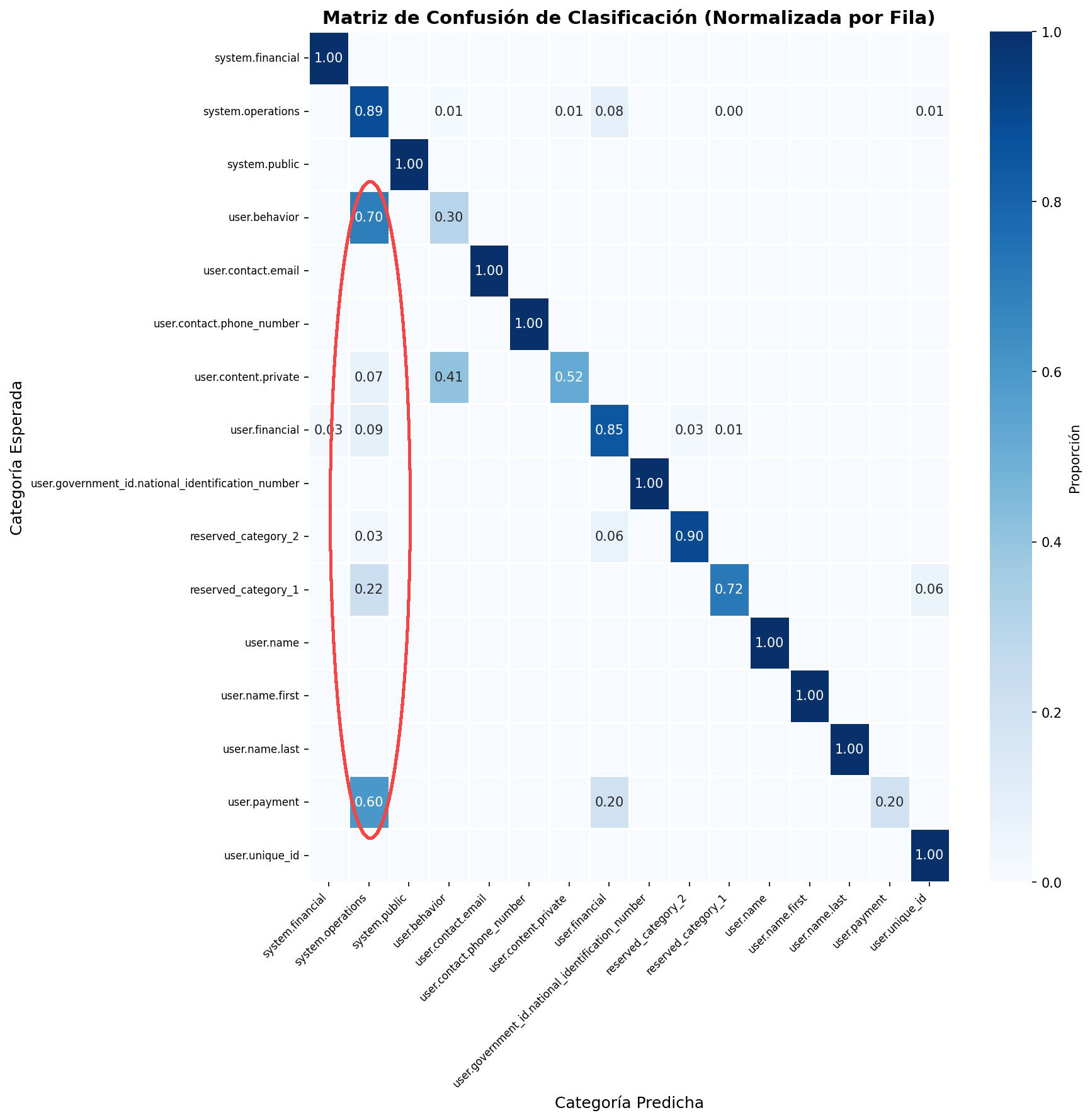
Desde la perspectiva de riesgo, estos errores tienen bajo impacto. Es relevante aclarar que user.payment en nuestra taxonomía no se refiere a datos financieros sensibles como números de tarjeta de crédito; estos se clasifican aparte como user.financial.credit_card y la herramienta los identificó correctamente.
En su lugar, la categoría user.payment agrupa campos como métodos de pago y fechas de transacción. Datos personales, sí, pero no sensibles según la ley.
Donde más importa la precisión, la herramienta muestra tasas de acierto significativamente más altas.
Estas son solo las primeras iteraciones. La idea es tomar los errores que aparecen y usarlos para seguir mejorando el clasificador.
Hay un punto que merece mención aparte. La clasificación manual que usamos como referencia tampoco es infalible. Durante la construcción del golden dataset, al revisar los mismos campos en distintos días, encontramos algunas inconsistencias en nuestras propias clasificaciones manuales previas (que intentamos corregir lo mejor posible) . Después de cientos de campos, es normal que uno comience a marearse un poco. Los nombres se confunden, el contexto se pierde y el criterio se vuelve inconsistente.
Esta experiencia refuerza algo que hemos sostenido desde el inicio: la clasificación manual no escala. Nosotros mismos lo vivimos. Y no es solo una cuestión de tiempo o costo, también es la fatiga cognitiva que se acumula e introduce errores que merman la calidad del resultado.
La clasificación automática de las tablas de prueba tomó aproximadamente 3 horas.
La clasificación manual tomó más de 5 días de trabajo completos.
Esto no significa que la automatización reemplace el juicio humano. Al contrario, lo que permite es concentrar ese juicio donde realmente aporta valor. La revisión humana sigue siendo relevante para validar casos ambiguos, ajustar criterios y detectar patrones que el modelo no captura, pero deja de ser el cuello de botella que frena la evolución del sistema.
Automatización del proceso: indispensable
Una clasificación automática bien diseñada no es solo un plus, sino que a largo plazo se vuelve indispensable. Esto se debe a que la realidad de los sistemas modernos es dinámica y cualquier enfoque estático queda obsoleto rápidamente.
La automatización permite sentar bases reales de gobernanza de datos dentro de una organización. Hace posible trabajar con agilidad, pero sin perder fidelidad respecto de lo que ocurre en el sistema. Así, se convierte en un insumo confiable para otros artefactos como avisos de privacidad, políticas internas, RATs, EIPDs, PIAs y procesos de gestión de derechos.
Además, una clasificación automatizada conversa de forma natural con los dominios de seguridad de la información. Modelos como ABAC o RBAC requieren una comprensión fina de qué datos existen y bajo qué condiciones deberían ser accesibles. Sin una clasificación consistente, estos controles terminan siendo ineficaces.
Desde el punto de vista operativo, la automatización aporta un criterio uniforme , sin las variaciones propias del juicio humano y libera carga de los equipos técnicos y legales, permitiéndoles concentrarse en otras tareas.
Todo esto encarna en su esencia los principios de Privacy by Design e implica una postura proactiva e integrativa de la privacidad en el diseño del sistema.
En esa línea, nuestra herramienta de clasificación está pensada para ser un servicio continuo , que se puede conectar a los repositorios de código (GitHub, GitLab) y plataformas (SAP, Salesforce), detectar diferencias y aplicar la clasificación cuando corresponde (por ejemplo, cuando se incorporan nuevos datos o un nuevo proceso).
De este modo, la clasificación evoluciona junto con la organización y se mantiene alineada con lo que efectivamente está en producción, sin necesidad de reclasificar todo el sistema en cada iteración.
Porque, en última instancia, la privacidad solo existe cuando acompaña al sistema tal como es, no como creemos que debería ser.
¿Necesitas resolver este problema? Nosotros sabemos cómo.
❤️ Este artículo fue 100% escrito por humanos