Actualmente, se estima que a nivel global se generan del orden de cientos de millones de terabytes de información por día. Datos que, una vez liberados en la jungla digital, se comportan como desechos radiactivos: fuera de tu control, asegurar su eliminación real es prácticamente imposible. Damos tanta información, y tan íntima, que incluso el historial de búsqueda de una persona funciona como una huella digital conductual: permite identificar a un individuo de forma única sólo a partir de los sitios que ha visitado a lo largo del tiempo.
Los volúmenes de datos no dejan de crecer. En un contexto donde 1+1 > 2 (es decir, que la información resultante de combinar dos trozos de data es, en muchas ocasiones, mayor que la suma de sus partes por separado) se hace esencial protegerlos.
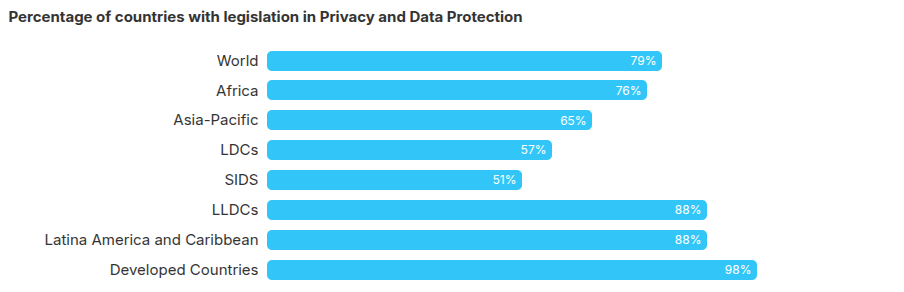
Y así lo han reconocido la mayoría de los países en el mundo: según la UNCTAD a julio de 2025, 79% de los países contaban con legislación relativa a privacidad y protección de datos personales. Chile, afortunadamente, no ha sido la excepción.
El caso de Chile: de una ley simbólica a un marco real
La primera ley que hace referencia a la protección de datos personales en nuestro país, la Ley 19.628 Sobre la Protección de la Vida Privada, fue promulgada en agosto de 1999. Este, sin embargo, fue un primer intento bastante débil: la falta de exigencias fuertes para que las organizaciones entendieran qué datos tenían y que hacían con ellos, junto con la inexistencia de sanciones proporcionales, la convirtió en una ley de papel.
En términos prácticos, podías incumplirla durante años sin que pasara nada.
Sin embargo, con el tiempo el escenario comenzó a cambiar. La adopción de marcos regulatorios más exigentes en otras jurisdicciones (como GDPR en Europa y la CCPA en California) puso en evidencia que una legislación débil ya no era suficiente para participar plenamente en la economía digital global. Estas normas no solo establecieron estándares más altos de protección de datos, sino que también condicionaron el comercio internacional y las inversiones, al exigir que las empresas que tratan datos de ciudadanos bajo esos regímenes cumplieran con requisitos estrictos para transferir o procesar información.
En ese contexto, la presión por modernizar el marco chileno creció, tanto por razones de competitividad como de protección de derechos, dando pie a múltiples iniciativas legislativas y debates sobre una reforma profunda en esta materia.
Tras unos largos 13 años en el congreso, en noviembre de 2024 se promulgó la Ley 21.719, que Regula la Protección y el Tratamiento de los Datos Personales y Crea la Agencia de Protección de Datos Personales, introduciendo importantes modificaciones a la ley del 99.
Con la entrada en vigencia de la Ley 21.719 en diciembre de 2026, las empresas tienen menos de 11 meses para prepararse a este cambio de paradigma. Ahora se exige demostrar control real sobre los datos. Cumplimiento de verdad, respaldado con una agencia fiscalizadora y multas que pueden alcanzar hasta 20.000 UTM y en casos de reincidencia pueden triplicarse hasta 60.000 UTM. Para empresas grandes, las sanciones pueden calcularse también como un 4% de los ingresos anuales en infracciones gravísimas. Además, si no se adoptan medidas correctivas oportunas, las multas pueden recargarse hasta en un 50%. Todo esto, sin considerar aún el riesgo reputacional devastador que puede tener un data breach.
Rigiendo para todas las organizaciones públicas y privadas que trabajen con datos personales - es decir, de personas naturales identificadas o identificables - la nueva normativa exige básicamente:
- La existencia de bases legales pertinentes para cada tratamiento.
- Control sobre terceros.
- Gestión de riesgos (PIA / RAT).
- Ejercicio efectivo de derechos (ARSOP).
- Seguridad proporcional al tipo de dato.
Todo parte por la clasificación de datos
Considerando las exigencias que introduce la Ley 21.719, es natural que cuando las organizaciones piensen en privacidad, la preocupación se centre hacia lo que se ve “desde afuera”, lo más evidente y de cara al usuario, como los avisos de privacidad, los checkboxes de consentimiento, la gestión de derechos ARSOP. Un poco más allá, registro de actividades y estrategias de mitigación.
Lamentablemente esto resulta ser solamente la punta del iceberg. Problemas estructurales, de mayor complejidad, son los que se esconden bajo el agua y afectan profundamente a la mayoría de empresas.

Si bien esto es tremendamente alarmante, es consecuencia esperable de la poca cultura de privacidad que existe. Son muy pocas las organizaciones que reconocen como problema central la falta de clasificación de datos y aún así la mayoría te dirá que no sabe qué datos tiene ( de quién son, de qué tipo, cuál es el volumen) , dónde los tiene (en qué base de dato, país o región del servidor donde almacena) y qué hace con ellos.
En la práctica, la clasificación de datos es el cimiento sobre el que se apoya todo el cumplimiento de privacidad. Sin ella, todo lo demás es meramente declarativo. Se pueden tener avisos de privacidad impecables y políticas de tratamiento bien redactadas, pero estarán basadas en lo que crees que hace la empresa, no en lo que realmente ocurre.
La fuente de verdad no está solamente en los documentos, sino también las bases de datos, en los sistemas y en la infraestructura donde los datos viven y se mueven. Cuando no se parte desde allí, se terminan documentando intenciones en lugar de operaciones. La clasificación es precisamente lo que permite cerrar esa brecha, y por eso es un paso indispensable y crítico para cualquier cumplimiento en privacidad.
Porque si no sabemos qué datos tenemos, simplemente no hay forma de tratarlos, resguardarlos ni reportarlos correctamente. Por consiguiente, tampoco podremos cumplir con las regulaciones pertinentes.
Este es un problema más complejo de lo que parece
Más allá de ser la base sobre la que se sostiene todo el cumplimiento de privacidad, este es el desafío más complejo que enfrentan las organizaciones hoy: la mayoría de las empresas no sabe qué datos tiene y lleva años funcionando así. Por esta razón, no saben cómo empezar a desenmarañar esta madeja: supone una inversión sustancial de dinero y tiempo, sumado a un nivel de conocimiento especializado en privacidad que, en general, está ausente.
Intuitivamente, lo primero que surje como idea es clasificar los datos de forma manual. Mirarías uno a uno los datos, intentarías entender qué significan, de quienes son y como se ocupan y en base a aquello, una taxonomia propia y criterios internos los clasificarías. ¿Fácil? Ahora imagina que tienes 600, 800, miles de tablas con datos, cada una con 5, 10, o más de 20 columnas. Tendrías que revisar, a mano, cada uno de esos miles o millones de casos.
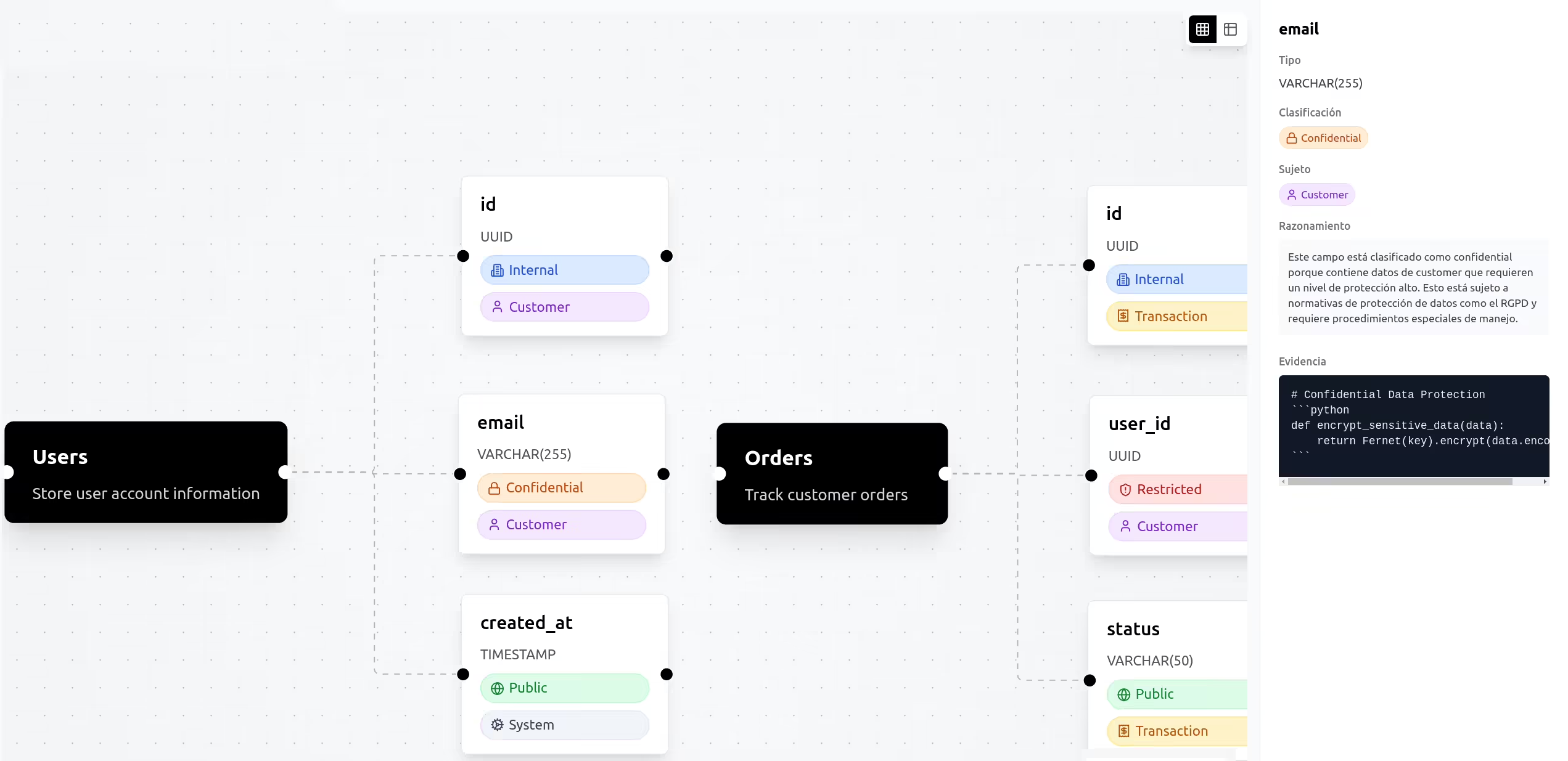
Este acercamiento no sólo resulta prácticamente imposible por cuestiones de tiempo , sino que presenta otros desafíos: tablas con nombres poco descriptivos (como "atributo_1", "simbolo_3", etc) requieren contexto adicional para entender a qué hacen alusión. Entonces, ¿cómo lo resuelves? ¿lees código fuente? ¿documentación (si es que existe)? Ya estarías con un desarrollador estancado únicamente en esta tarea durante meses, lo que resulta carísimo para cualquier empresa.
Y lo peor de todo: después de varios meses de trabajo, cuando finalmente termines, el código habrá mutado. ¿Cómo sigues el ritmo?
Imaginemos que para lograr la clasificación en menos tiempo, en vez de tener a una sola persona abocada a esta tarea ahora son dos, o todo un equipo. ¿Te has dado cuenta de lo difícil que es compartir criterios entre más de una persona?
Incluso siendo uno solo, la apreciación y forma de juzgar, ponderar y contextualizar información para clasificarla va variando , a veces de día a día. Reflexionamos algo, leímos algo nuevo que nos hizo cambiar de parecer, o puede ser que con más información formamos otro criterio. Tal vez incluso no nos acordamos bien cuál fue la lógica original que usamos para discernir en casos ambiguos (que son más de los que seguramente piensas). Cuando esto ya lo hemos aplicado en 200 tablas atrás, si luego cambiamos de opinión, ¿qué procede? ¿volver a revisar todo? No es escalable.
Aquí es donde surgen diferentes alternativas de clasificación automática, intentando homogeneizar criterios, ahorrar tiempo e implementar uno de los pilares de privacy by design: conocer qué datos se tienen desde el origen. Existen diversos enfoques, algunos más tradicionales como análisis sintáctico de código hasta otros más vanguardistas con inteligencia artificial, cada uno con sus propias ventajas y limitaciones. La clasificación automatizada de datos sigue siendo un problema abierto.
No hay una bala de plata, pero la combinación de estrategias como análisis sintáctico con tecnología avanzada (LLMs), supervisión humana estratégica y procesos iterativos de refinamiento parece ser el camino más prometedor en esta materia.
En Privai construimos exactamente eso: una solución de clasificación automatizada que combina tecnología de última generación con el contexto real de tu negocio , diseñada por ingenieros expertos en el área para empresas que no tienen años para invertir ni equipos gigantes dedicados a privacidad.
En el próximo post te contamos cómo nosotros resolvimos el problema de clasificación.
Diciembre de 2026 no espera. ¿Necesitas ayuda? Contáctanos.
❤️ Este articulo es 100% human made.